
VAST+清华提出3D生成新范式,空间智能密度控制「把算力花在刀刃上」| SIGGRAPH 2026
VAST+清华提出3D生成新范式,空间智能密度控制「把算力花在刀刃上」| SIGGRAPH 2026如果把现在最热门的几条 3D 生成技术线放在一起看,你会发现它们正在遇到一个很像的问题。
来自主题: AI技术研报
6404 点击 2026-05-21 16:08
 搜索
搜索
如果把现在最热门的几条 3D 生成技术线放在一起看,你会发现它们正在遇到一个很像的问题。
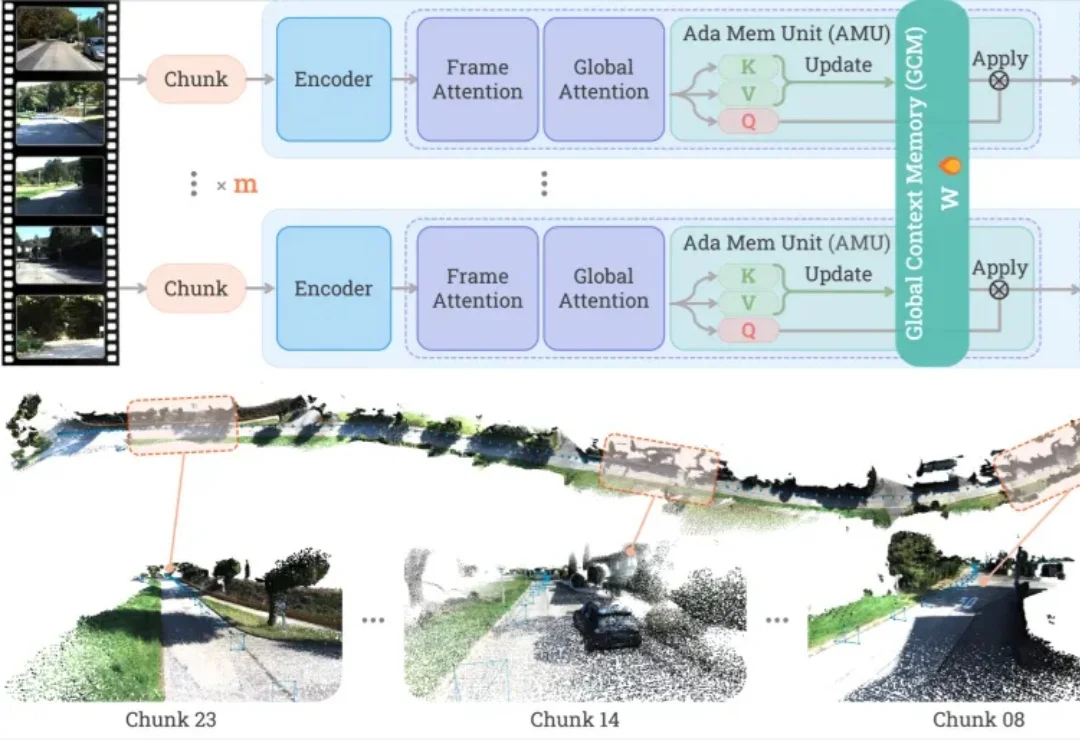
长视频 3D 重建最怕的,其实不是 "看不清"。
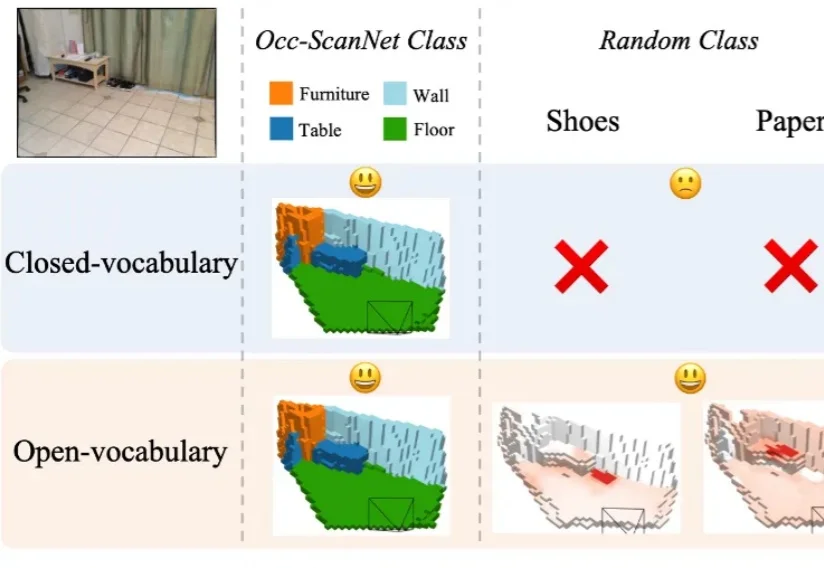
在具身智能研究中,如何让智能体精准理解周围环境的精细几何结构与开放语义信息,始终是具身感知的核心难题。近年来,语义占据预测(Semantic Occupancy Prediction) 将稠密几何与语义信息统一到三维体素网格中,用于构建 3D 语义占据地图,为机器人的空间推理、导航与交互操作提供了场景表达基础。
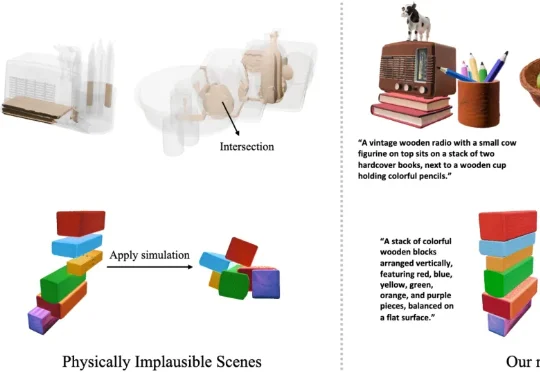
现在的 3D AIGC 已经可以很快生成场景,但离真正落地还有一段距离。很多场景看起来还行,一进物理模拟就会暴露问题,比如物体悬空、互相穿插,甚至还没碰就散。这些问题让它们很难直接用于游戏、XR 或机器人等实际场景。

在真正熟悉3D高斯泼溅技术的圈子里,“大规模3D高斯模型在移动端打开” 的技术早已不是什么新鲜事。两年前就有一家深圳创业公司,做出来并推出完整产品,甚至开源至GitHub。
谷歌还在闭源守宝,NVIDIA已把Lyra 2.0全开源:35步去噪变4步,2D图片直出3D高斯泼溅+网格。社交狂欢背后,是对具身AI仿真的巨大潜力——以后造世界,不用再去真实世界采数据了。

而我们之所以注意到这种玩法,是因为最近一则醒目的消息:3D 打印界扛把子拓竹的模型平台 MakerWorld 迎来了一位新盟友 —— 胡渊鸣创立的 Meshy AI。提起胡渊鸣,机器之心的读者应该都不陌生。2019 年,我们就开始报道他的计算机图形库「太極」。2020 年,他因用 99 行代码复刻《冰雪奇缘》积雪物理特效被大众所熟知,登顶社交媒体热搜。如今,多年过去,他已经在新的赛道领跑。

从单幅图像恢复三维结构,到多视图场景建模、动态 4D 重建,再到机器人、自动驾驶、SLAM 与视频生成,如何让模型在不依赖逐场景优化的前提下,直接、高效地理解并重建三维世界,正在成为 3D 视觉领域的
作者|周一笑 邮箱|zhouyixiao@pingwest.com 2026 年 3 月 17 日,拓竹科技把 Meshy 6 接进了 MakerWorld 的 MakerLab。一张照片上传上去,两

当文字、图像、视频已经先后被生成式 AI 重写,3D 很可能就是下一站。